Инструкция
Загрузка файлов
Блок загрузки контента:
По формату
Ссылка
Ссылка может быть на файл или на YouTube:
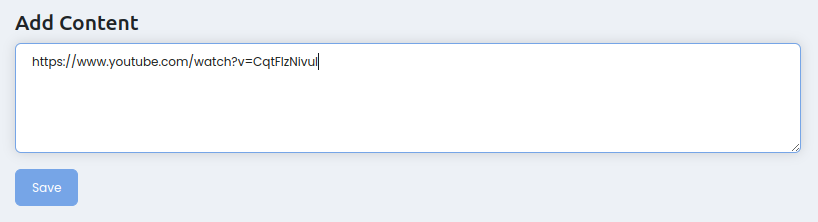
Файл
Нажимаем Attach Files -> Выбираем все нужные файлы -> Нажимаем Upload:
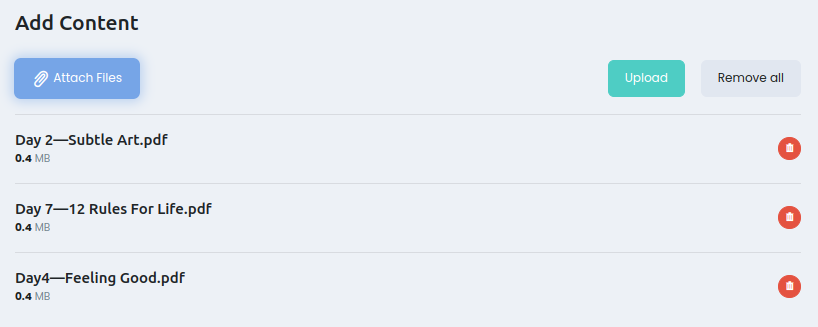
Возможные форматы: webm, mp4, ogg, mp3, pdf, txt, epub, md, jpg, png.
Максимальный вес: 1Гб
Текст
Просто вставляем текст в поле и нажимаем Save:
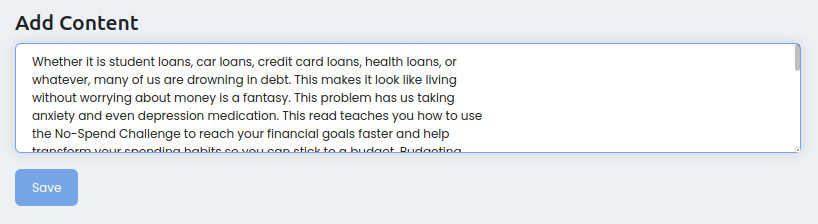
По типу
Видео
Видео можно загрузить напрямую как файл, по ссылке, или по ссылке на Youtube. При этом если это youtube плейлист (ссылка вида https://www.youtube.com/playlist?list=), то будет создана папка, а в ней все видео.
Как происходит обработка видео:
- Если это youtube/ссылка, то оно скачивается
- Выделяется аудио дорожка
- Распознавание аудио -> текст
После обработки, видео можно смотреть прямо в Lexicly. А также можно: слушать аудио, скачать видео в виде файла, и скачать аудио. Да, всё правильно, можно скачать видео с youtube или смотреть без VPN.
Доступные форматы: webm, mp4.
Аудио
Аудио можно загрузить напрямую как файл, так и по ссылке. Аудио можно слушать в Lexicly, а можно скачать.
Доступные форматы: ogg, mp3.
Документы и тексты
Можно ввести текст напрямую, а можно загрузить документ как файл или по ссылке.
Доступные форматы: pdf, txt, epub, md
Изображения с текстом
Вы можете сфоторафировать документ или сделать скриншот, Lexicly распознает текст.
Доступные форматы: jpg, png
Время обработки
После того как контент загружен, проходит 2 этапа:
- Преобразование в текст
- Обработка текста
Время на эти этапы может быть разным. Преобразование зависит от исходного формата и объёма файла. Видео на 2 часа будет обрабатываться долго, полчаса примерно. Обработка текста тоже зависит от объёма и от сложности лексики, насколько далека лексика от словарной и от разнообразия слов. Для примера, 500 тысяч знаков (средняя книга) будет обрабатываться час. Плюс, при загрузке большого количества файлов, они будут вставать в очередь.
Папки и файлы
Добавление папок
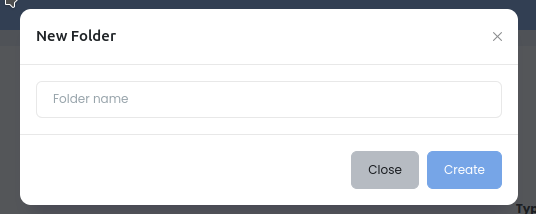
Кнопка Add Folder -> Create:
Переименование / перенос файлов и папок
Заходим внутрь файла / папки:

Нажимаем на Edit:
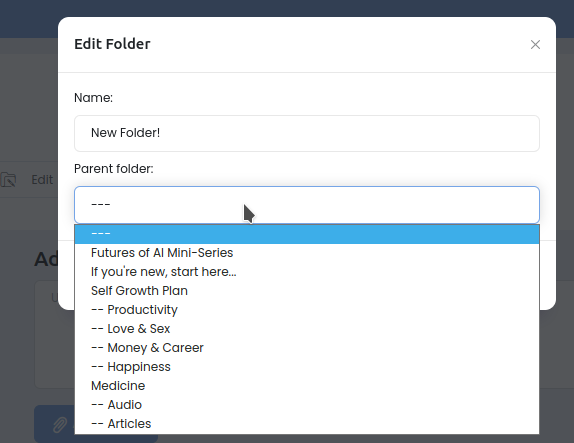
Редактируем имя файла/папки и родительскую папку.
Удаление файла / папки
Заходим внутрь файла / папки:

Нажимаем на кнопку удаления:
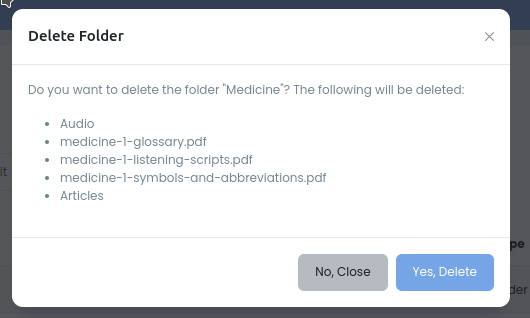
Просмотр файлов
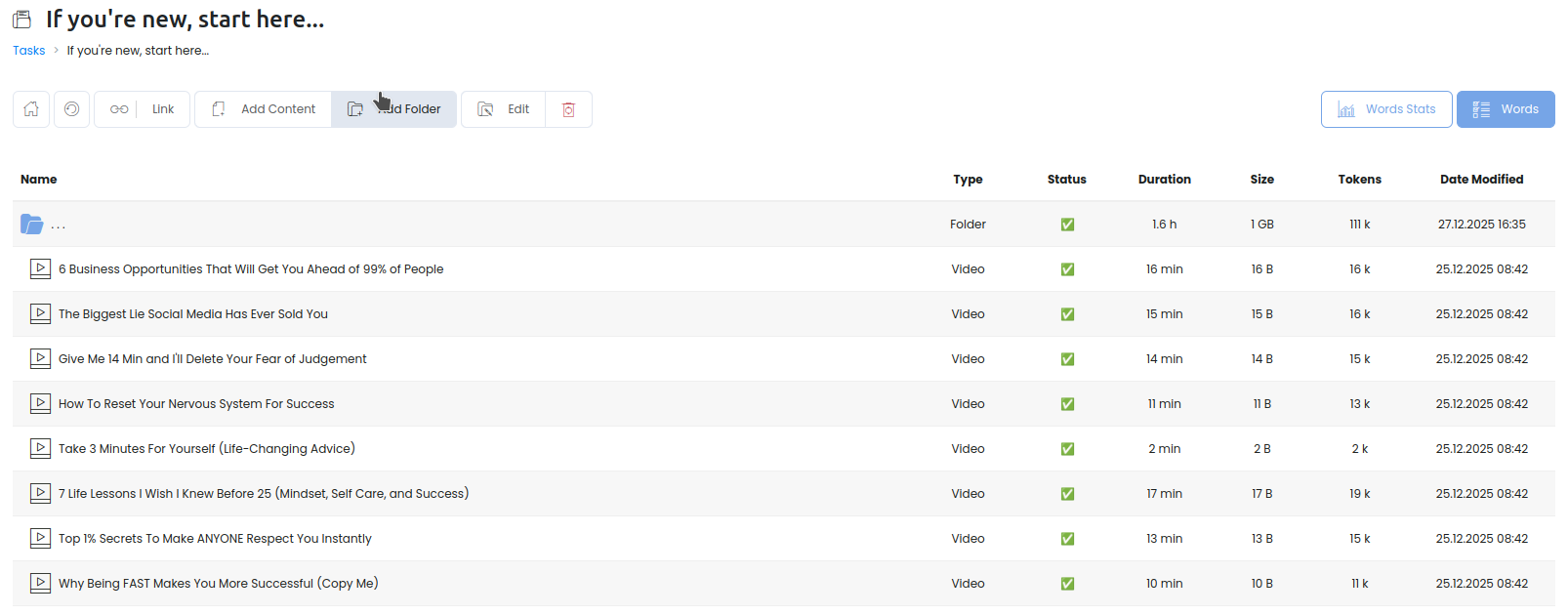
Так выглядит содержимое папки (в данном случае это был плейлист youtube):
Так выглядит если зайти внутрь файла (это видео):
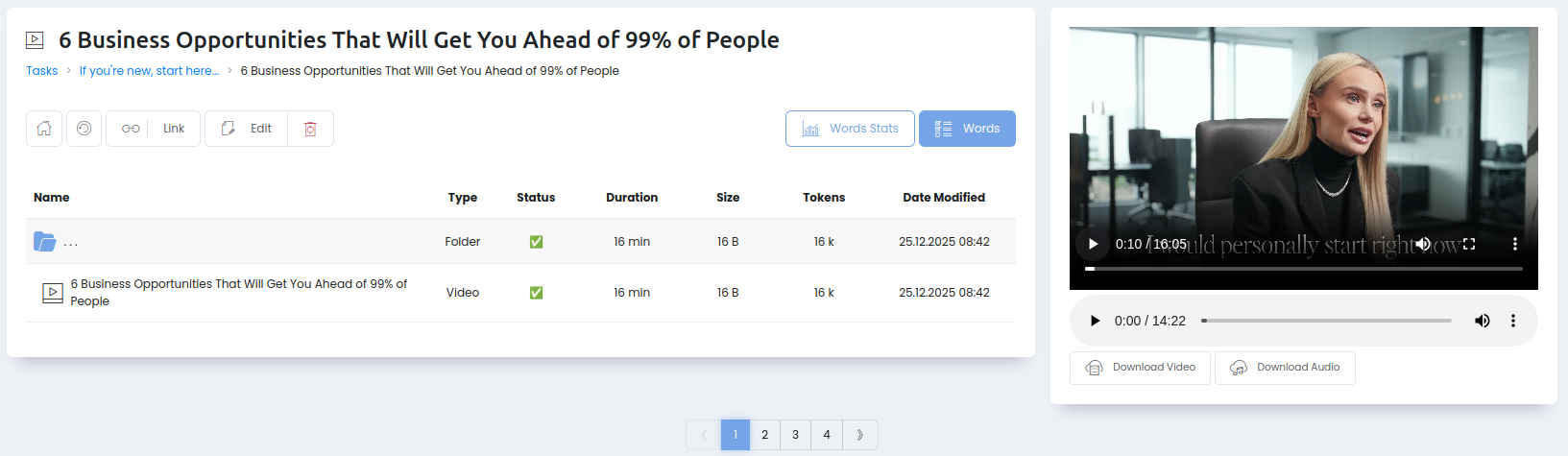
Слева направо кнопки:
- На главую (корень)
- Обновить страницу
- Link — исходная ссылка (в данном случае ведёт на youtube). Если контент получен из файла, тут будет кнопка "Download".
- Edit (редактирование файла) / Delete (удаление)
Если просмотр контента недоступен (это просто документ), то правой части не будет.
Что такое "Word stats" и "Words", а также что внизу страницы, разберём далее.
Разбор контента
Содержимое файла доступно после первого этапа после загрузки (преобразование в текст), а сам разобранный контент доступен после второго этапа (обработка текста).
Содержимое разбивается на страницы, в каждой не более 5 тыс. символов:

Внутри каждой страницы есть несколько режимов. О них речь далее.
Content
Просто исходный текст:

Принимается только текст на английском, все сомнительные участки контента пропускаются, поэтому вы можете увидеть пробелы в тексте. А также надо учитывать то какой формат был изначально, если это видео/аудио/ не структурированный документ, то преобразование будет не 100% точным.
Words
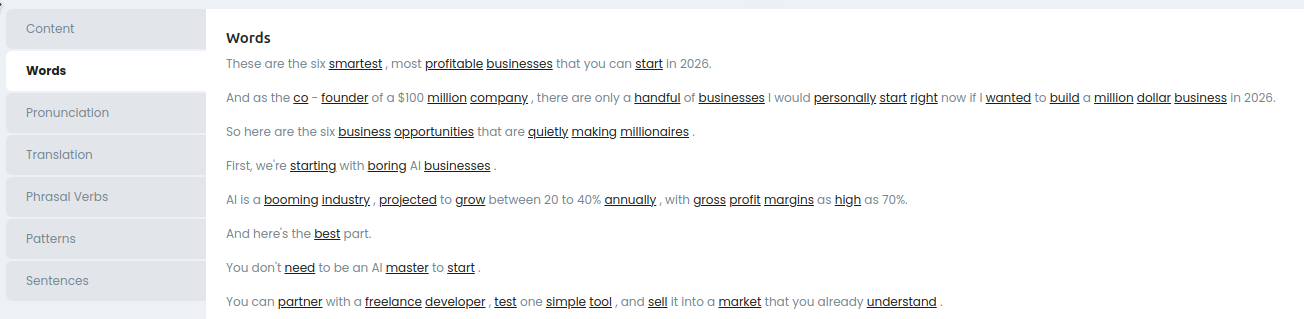
Подсвечены слова, найденные в словаре, со ссылками на словарь. (К словарю ещё вернёмся)
Pronunciation
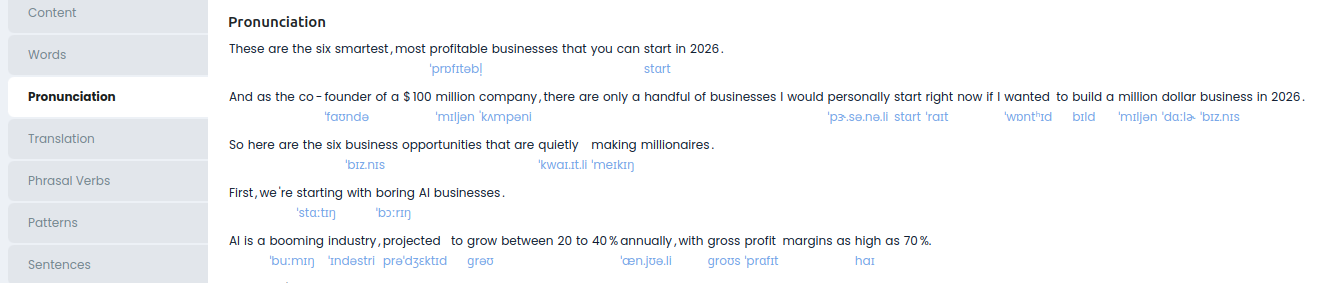
Дана транскрипция слов, найденных в словаре, причём именно в той форме которая встречаются в тексте. Есть 2 варианта транскрипции: общая/ US/ UK. В данном случае выбрана US (это настраивается в профиле).
Translation
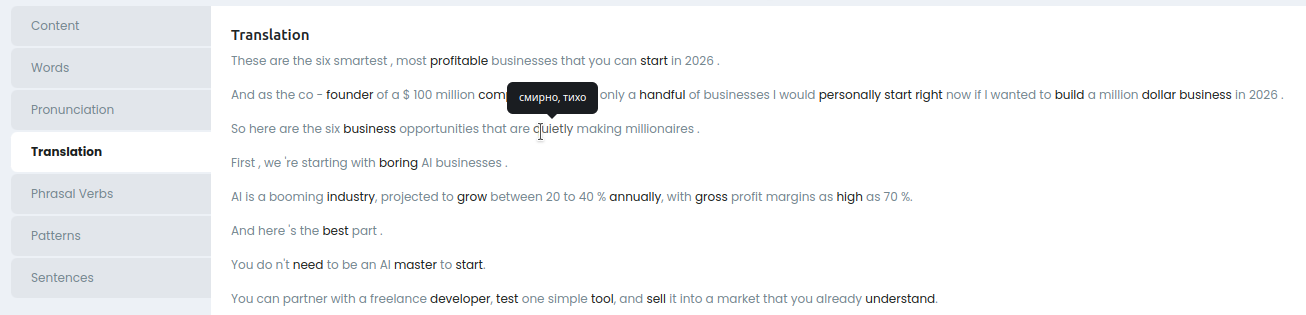
Перевод на русский.
Phrasal Verbs
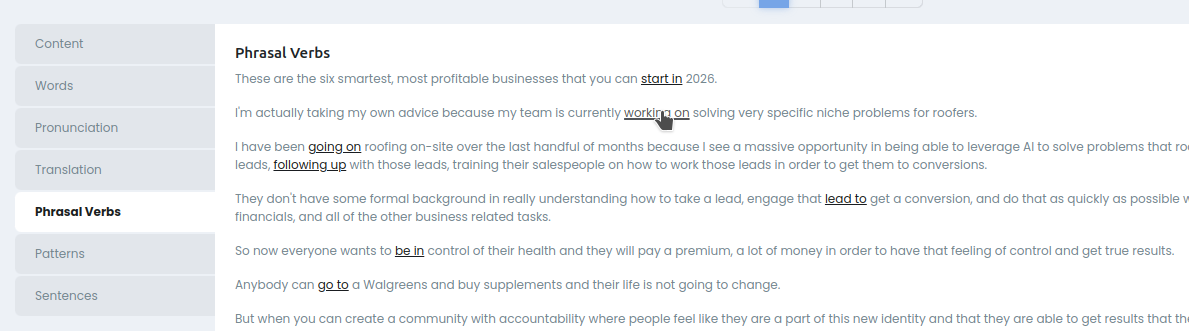
Подсвечены фразовые глаголы со ссылкой на словарь.
Patterns
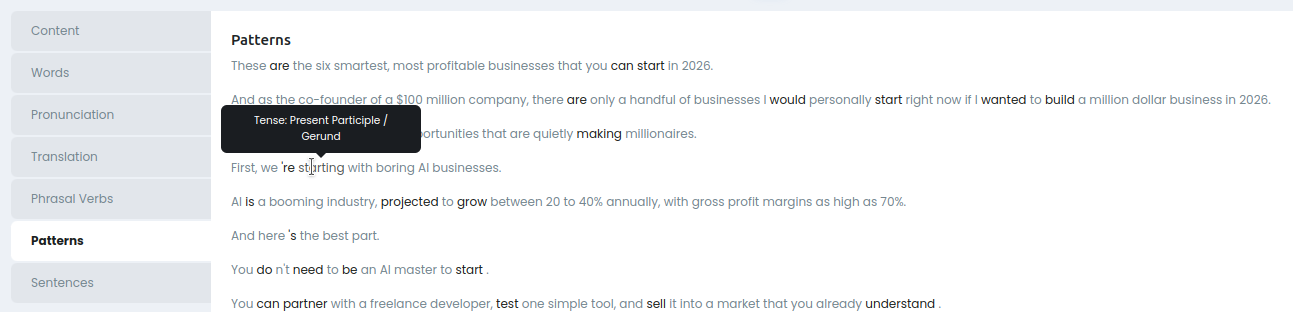
Подсвечены найденные грамматические паттерны.
Sentences
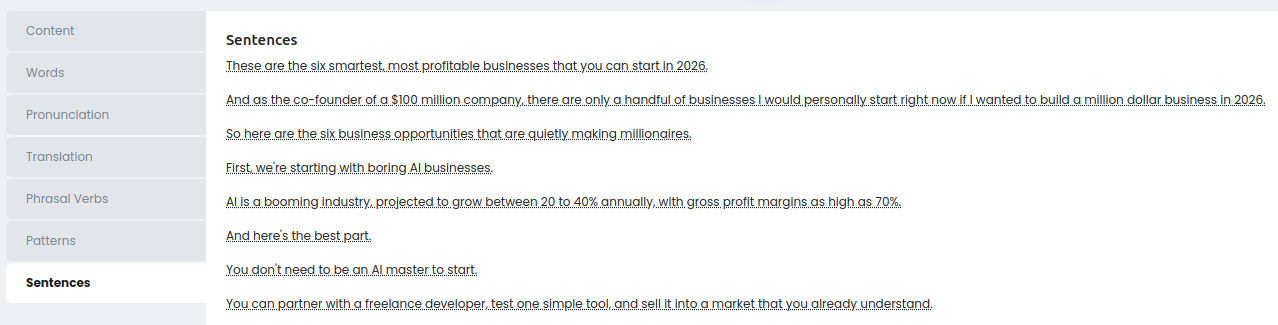
Всё то же самое, но с группировкой по предложениям + внутри есть перевод всего предложения:

Словарь и статистика
Работа со словарём
Словарь, может соответствовать файлу, папке, или вообще всему загруженному контенту:
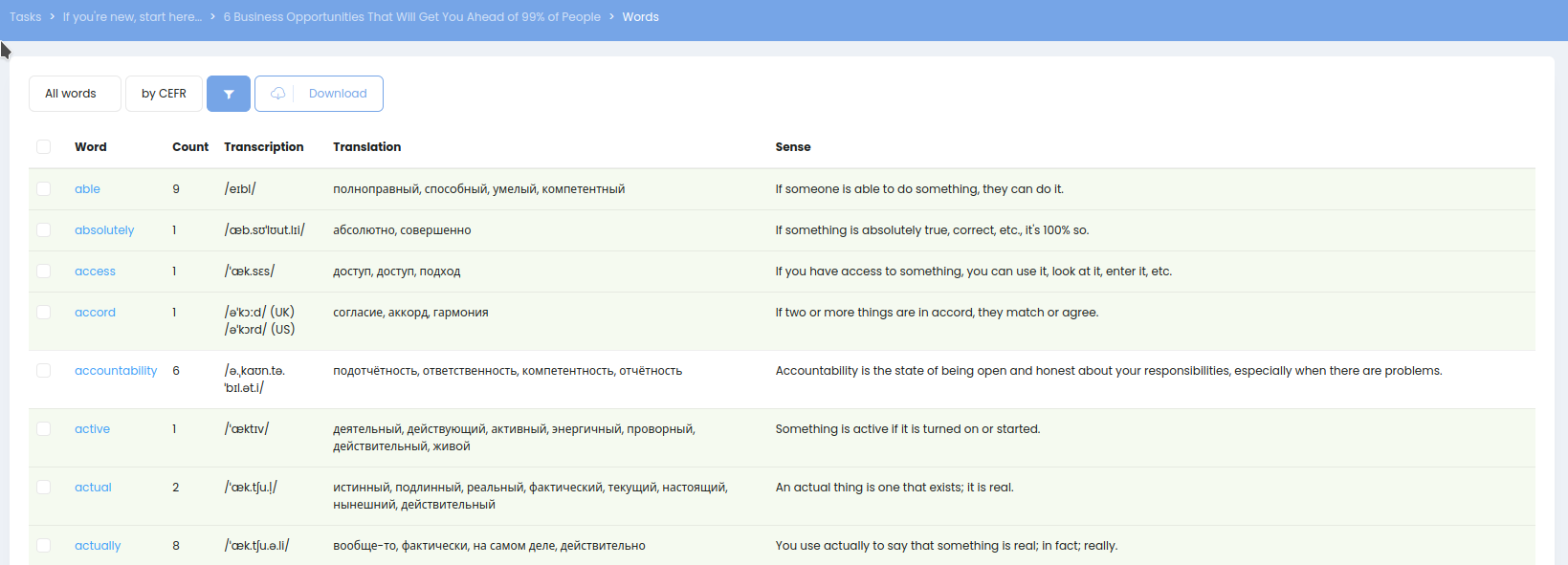
Зелёным подсвечены слова, которые помечены как знакомые.
Чтобы добавить слова в список знакомых, нужно выбрать их и нажать на Mark as Known:

Аналогично можно убрать из списка знакомых или удалить. Знакомые слова общие для всего контента пользователя.
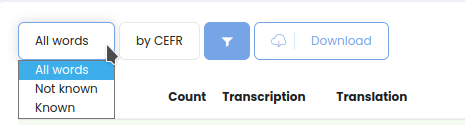
Фильтры:
Фильтр по тому, какие слова отображать: знакомые, незнакомые, все:
Фильтр по уровню CEFR:
Вы можете выбрать все из A1, и сразу отметить их все известными, чтобы больше они не попадались на глаза.
По умолчанию сортировка по алфавиту, можно нажать на Count, и отсортируется по частоте встречаемости:
Count - это частота в данном файле / папке или вообще, зависит от того, какие слова вы смотрите.
Если слово ошибочное, например ошибка парсинга, либо не несёт смысловой нагрузки, то его можно просто удалить. Например, oh, wow и т.д.
Можно скачать словарь неизвестных слов, для этого рассортируйте слова и нажмите на Download. Будут скачаны все слова, не удалённые и не отмеченные как знакомые, в алфавитном порядке, колонки: слово, транскрипция, перевод. Этот файл можно загрузить в приложение для изучения слов.
Статистика
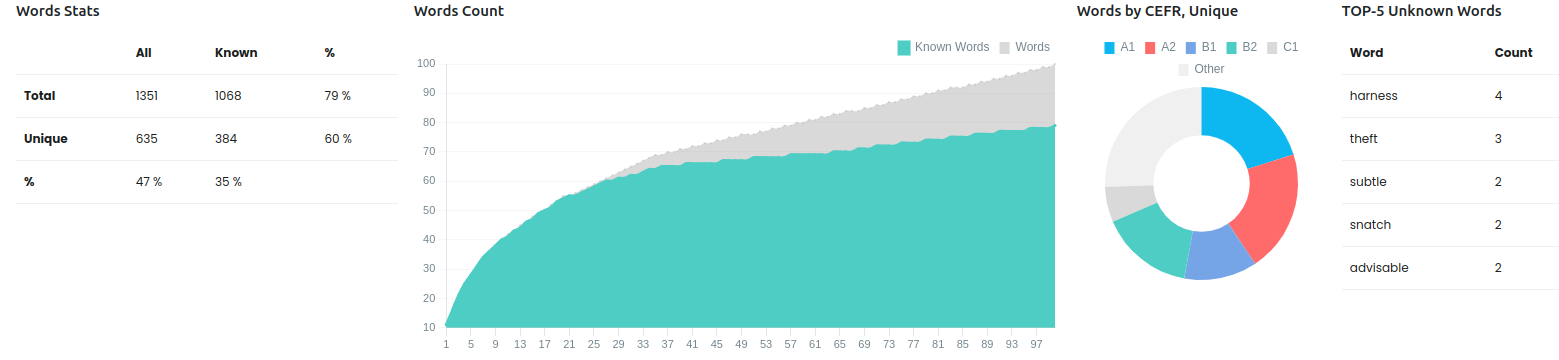
Пример того как выглядит статистика слов для файла:
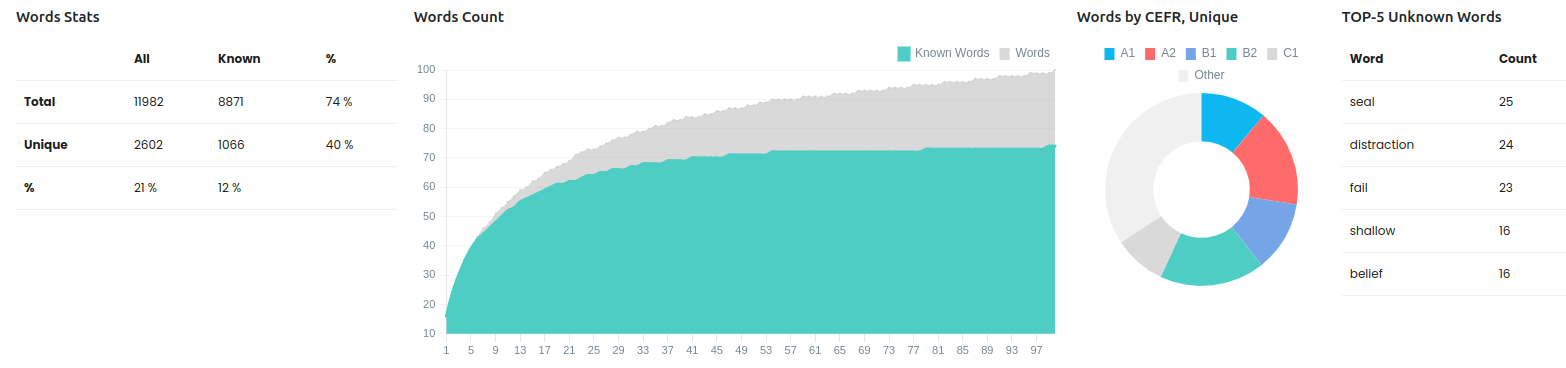
Пример для папки, в которую входит этот файл:
Далее рассмотрим что значат отдельные графики.
Words Stats
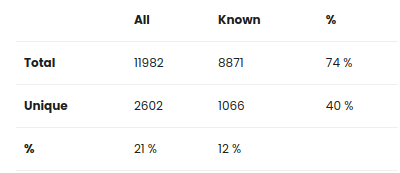
- Total - All = Сколько всего слов
- Total - Known = Сколько из них знакомых
- Unique - All = Сколько всего уникальных слов в тексте
- Unique - Known = Сколько известных уникальных слов в тексте
74% = это соотношение Total - Known / Total - All = Сколько процентов текста я понимаю
40% = это соотношение Unique - Known / Unique - All = Сколько процентов уникальных слов я понимаю
21% = это соотношение Unique - All / Total - All = Cколько уникальных слов в тексте, 21% уникальных, 79% слов повторяются. Чем больше текст, тем меньше этот процент.
12% = это соотношение Unique - Known / Unique - Known = Cколько процентов слов среди уникальных я знаю
Из этих цифр можно сделать вывод, что зная 12% слов, я понимаю 74% текста.
Words Count
Пример для маленького текста:
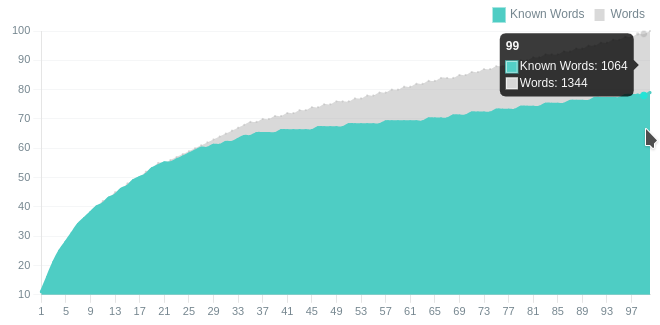
На этом графике серым показано, зная сколько % слов, сколько % текста можно понять. Зелёным показано, сколько вы знаете. Здесь видно, что я знаю почти все частотные слова.
Пример для большой книги:
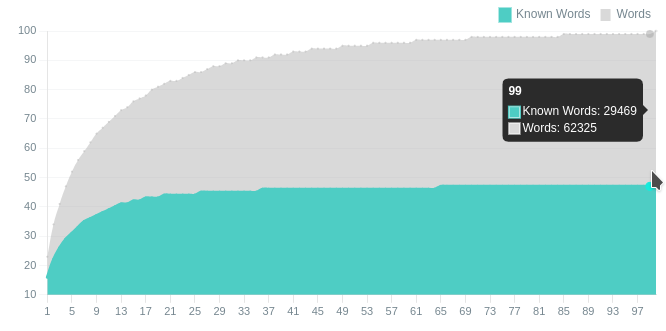
Чем больше текста, тем больше повторяющихся слов. И это видно на графике, он пологий. Зная 25% слов, вы сможете прочитать 85% книги. К середине книги большинство из них уже встретится, чем дальше, тем меньше новых слов будет встречаться и к концу книги будет читать совсем легко.
Шкалы в процентах, а внутри числа абсолютные. В этой книге 29 тысяч неуникальных слов.
Пример для специализированного (в данном случае это медицинский) контента:
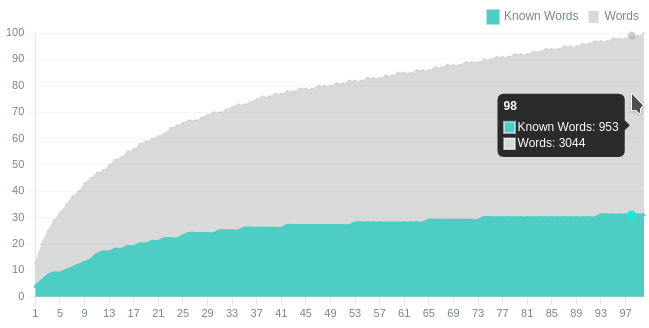
Здесь текст не очень большой, но даже частотные слова я не знаю, и могу прочитать всего 31% текста.
Words by CEFR, Unique
Все уникальные слова в тексте распределы на уровень по CEFR. Other - это слова, не найденные в входящие даже в уровень C1 либо не найденные в словаре.
Пример простого текста:
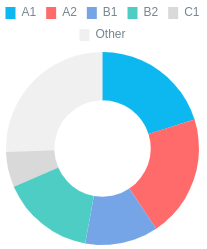
Cложный и большой:
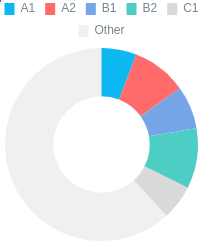
Медицинская статья:
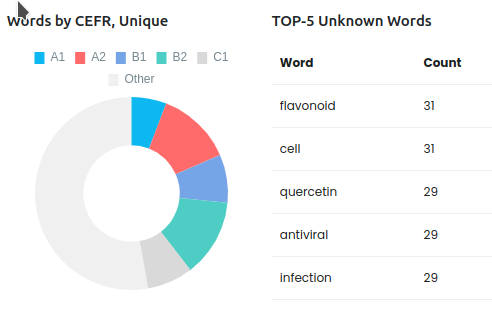
1100 уникальных слов, большинство из них не входят в C1.
Словарь
Для каждого найденного в словаре слова есть такая страница:
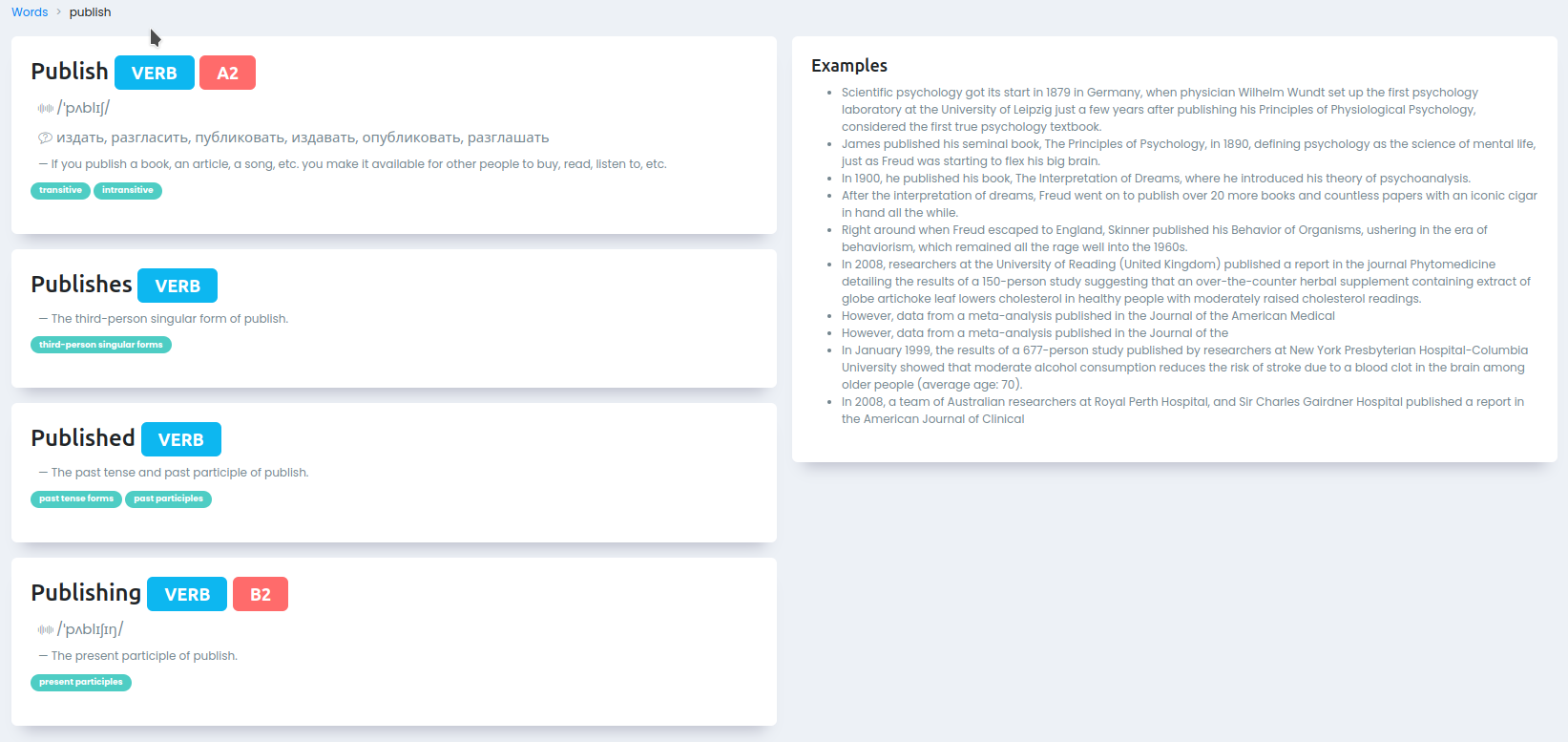
На ней показаны разные формы слова, произношение, переводы, значение и справа — примеры предложений, которые встречаются в ваших текстах.
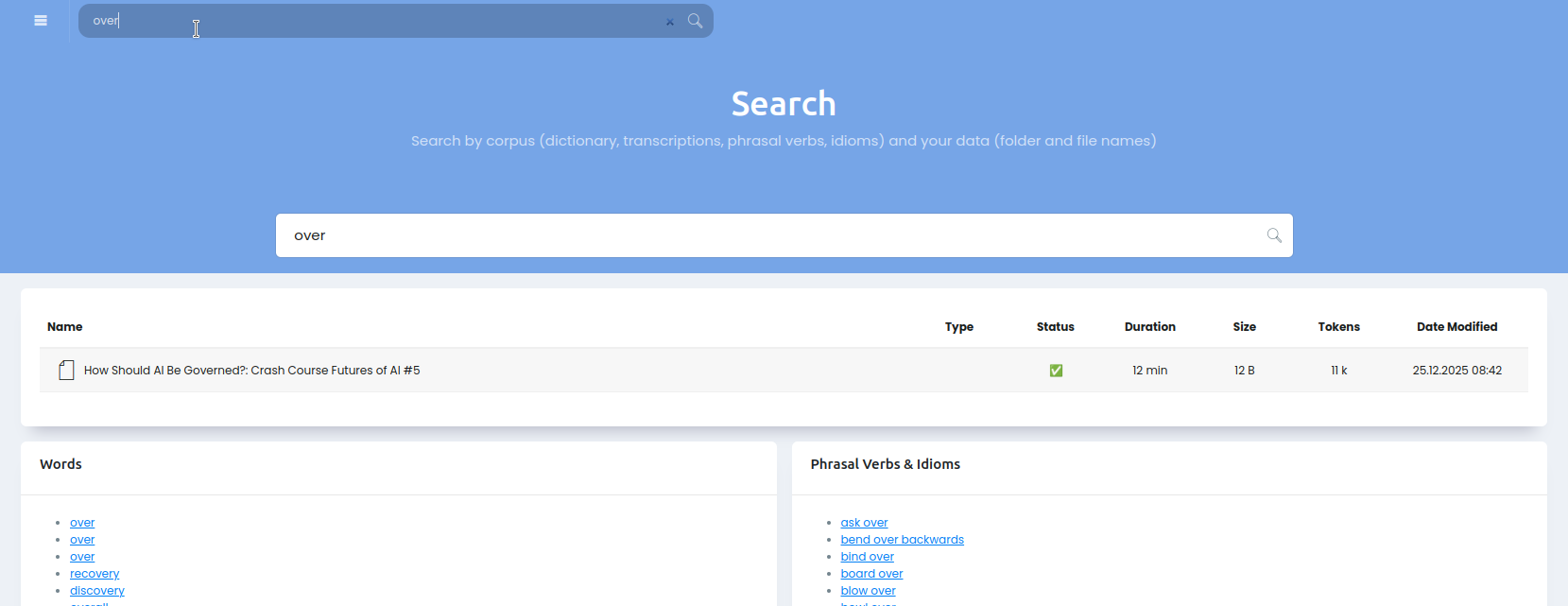
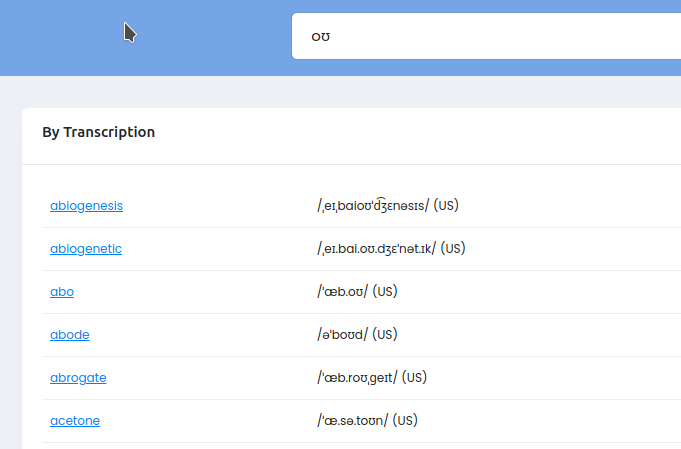
Поиск
Вверху личного кабинета есть строка поиска, через неё можно искать файлы и папки, а так же слова и транскрипции: